PDF-Chaos in der Spedition: Wie KI die Daten-Eingabe ins TMS automatisiert
In den Dispositionsabteilungen deutscher Speditionen stapeln sich täglich die PDFs. Frachtbriefe, T1-Zolldokumente, Lieferscheine, Packlisten.
09. Juni 2026
Frachtbriefe, T1-Zolldokumente, Lieferscheine, Packlisten, Excel-Anhänge und Freitext in E-Mails. In vielen Speditionen beginnt genau so der Tag in der Disposition. Erst wird geöffnet, dann gelesen, dann gesucht, dann abgetippt. Und am Ende landet das Wichtigste trotzdem oft mit Zeitverzug oder mit einem Zahlendreher im TMS.
Genau hier setzt KI-Auftragserfassung in der Spedition an. Nicht als Spielerei, sondern als operativer Hebel. Der Job von Disponenten ist schließlich nicht, PDFs zu entziffern. Ihr Job ist es, Transporte sauber zu planen, Engpässe früh zu erkennen und Kunden proaktiv zu betreuen.
Die schnelle Einordnung
- Das Problem: PDF- und E-Mail-basierte Auftragseingänge bremsen die Disposition täglich aus.
- Die eigentlichen Kosten: Nicht nur Zeitverlust, sondern auch Tippfehler, Medienbrüche, Rückfragen und Frust im Team.
- Die Lösung: Ein KI-Agent klassifiziert Dokumente, extrahiert relevante Daten, prüft sie gegen Regeln und übergibt sie ans TMS.
- Der operative Hebel: Disponenten bearbeiten nicht mehr jeden Auftrag vollständig, sondern nur noch Ausnahmen und Unklarheiten.
- Der Effekt: Weniger manuelle Dateneingabe, schnellere Auftragsanlage, mehr Zeit für Disposition statt Klebearbeit.
Das Ziel ist nicht, PDFs schöner auszulesen. Das Ziel ist, aus eingehenden Dokumenten automatisch einen dispo-fähigen Auftrag im TMS zu machen.
Ein teurer Vormittag in der Dispo
Manuelle Dateneingabe fühlt sich oft harmlos an, weil sie in kleinen Portionen passiert. Drei Minuten hier, vier Minuten dort, noch schnell ein Frachtbrief, noch schnell ein Zollpapier, noch schnell die Packliste prüfen.
In Summe entsteht daraus aber ein massiver operativer Verlust. Während ein Mitarbeiter Dokumente öffnet, Felder sucht und Daten ins TMS überträgt, passiert etwas anderes gerade nicht: Es wird keine Tour optimiert, kein Leerkilometer vermieden, kein Kunde aktiv informiert und kein Engpass sauber eskaliert.
Die teuerste Ressource im Backoffice wird für Bildschirm-Abtipparbeit verbraucht.
| Beispielrechnung | Wert |
|---|---|
| Dokumente pro Tag | 100 |
| Durchschnittliche Bearbeitungszeit pro Dokument | 3 Minuten |
| Gesamtzeit pro Tag | 300 Minuten |
| Gesamtzeit pro Tag in Stunden | 5 Stunden |
| Gesamtzeit pro Monat bei 22 Arbeitstagen | 110 Stunden |
Die Zahl muss nicht auf die Minute genau stimmen. Entscheidend ist das Muster: Schon bei mittlerem Auftragsvolumen verbrennt die Disposition schnell mehrere Stunden täglich für reine Datenerfassung.
Die unsichtbaren Kosten der Handarbeit
Der Zeitverlust ist nur die sichtbare Seite. Die unsichtbare Seite ist oft teurer.
- Ein Zahlendreher in der Postleitzahl erzeugt Zusatzaufwand in der Zustellung.
- Eine falsch übernommene Referenz erschwert Rückfragen und Abrechnung.
- Eine übersehene Gefahrgutangabe kann operative und rechtliche Folgen haben.
- Ein falsches Gewicht führt zu Fehlplanung bei Kapazität, Preis oder Fahrzeugwahl.
- Eine fehlende Pflichtangabe erzeugt Rückfragen, Schleifen und Verzögerung.
Dazu kommt der kulturelle Schaden. Gute Disponenten wollen disponieren. Wenn sie ihren Tag wie Datentypisten verbringen, sinkt nicht nur die Produktivität, sondern auch die Bindung ans Unternehmen.
Warum OCR allein das Problem nicht löst
Viele Unternehmen denken beim Thema Automatisierung zuerst an OCR. Das ist nachvollziehbar, aber zu kurz gedacht.
OCR liest Zeichen. Das ist nützlich. Aber die eigentliche Herausforderung in der Spedition ist nicht nur das Lesen von Buchstaben. Die eigentliche Herausforderung ist das Verstehen von Dokumenten mit wechselnden Layouts, unterschiedlichen Bezeichnungen, mehreren Sprachen, unsauberen Scans und fachlichen Abhängigkeiten.
Ein klassisches System kann Dir vielleicht den Text aus einem PDF ziehen. Ein moderner KI-Agent geht weiter. Er erkennt den Dokumenttyp, versteht, welche Information fachlich relevant ist, ordnet Felder sinnvoll zu und prüft, ob die Werte überhaupt plausibel zusammenpassen.
| Klassisches OCR | KI-gestützte Dokumentenverarbeitung |
|---|---|
| Liest Text aus dem Dokument. | Klassifiziert Dokumente und extrahiert relevante Felder. |
| Funktioniert gut bei stabilen, sauberen Formaten. | Kommt besser mit variierenden Layouts und Dokumenttypen zurecht. |
| Benötigt oft starre Regeln oder Templates. | Extrahiert nutzbare Informationen auf Basis von Kontext, Layout und Feldlogik. |
| Prüft kaum fachliche Zusammenhänge. | Kann Pflichtfelder, Plausibilitäten und Geschäftsregeln prüfen. |
| Liefert Text zurück. | Liefert strukturierte Daten für TMS, Workflow oder Freigabeprozess. |
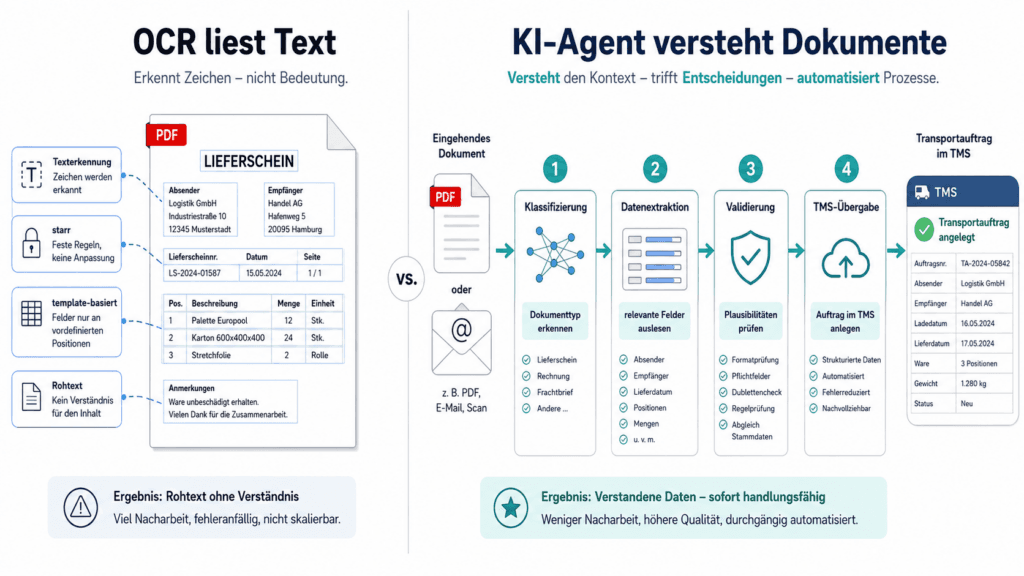
Die Grafik zeigt den Unterschied zwischen klassischer OCR und einem KI-Agenten für die Dokumentenverarbeitung in der Logistik. Links wird dargestellt, dass OCR vor allem Text aus einem PDF erkennt. Rechts wird gezeigt, wie ein KI-Agent eingehende Dokumente klassifiziert, Daten extrahiert, Plausibilitäten prüft und die Informationen für die TMS-Übergabe vorbereitet.So arbeitet der KI-Agent zwischen Postfach und TMS
Der entscheidende Denkwechsel lautet: Nicht der Mensch holt sich Informationen aus dem Dokument. Das System holt sich die Informationen und legt dem Menschen nur noch die Fälle vor, die wirklich Aufmerksamkeit brauchen.
- Eingang: Das Dokument landet im E-Mail-Postfach oder in einem definierten Eingangskanal.
- Klassifizierung: Der Agent erkennt, ob es sich um Frachtbrief, Lieferschein, Packliste, Zollpapier oder eine Kombination daraus handelt.
- Extraktion: Relevante Felder wie Versender, Empfänger, Referenzen, Mengen, Gewicht, Ladeadresse, Lieferadresse oder Termininformationen werden ausgelesen.
- Validierung: Pflichtfelder, Plausibilitäten und Abhängigkeiten werden geprüft. Fehlt etwas oder passt etwas nicht, wird markiert statt blind übernommen.
- Abgleich: Optional können Stammdaten, bekannte Kunden, Ladeorte oder Artikelreferenzen abgeglichen werden.
- Übergabe: Sind die Daten sauber, werden sie per API, Middleware oder Importlogik ans TMS übergeben.
- Ausnahmebehandlung: Nur Fälle mit Lücken, Widersprüchen oder niedriger Sicherheit landen im Prüf-Workflow des Teams.
Das Ergebnis ist kein theoretisches KI-Experiment, sondern ein neuer Betriebsmodus für den Auftragseingang.
Welche Daten typischerweise extrahiert werden
Je nach Transportart, Kunde und TMS unterscheiden sich die Pflichtfelder. Trotzdem gibt es typische Datenpunkte, die in fast jeder Spedition relevant sind.
| Dokumenttyp | Typische Felder | Warum relevant fürs TMS? |
|---|---|---|
| Frachtbrief | Versender, Empfänger, Referenzen, Warenbeschreibung, Gewichte, Sendungsdaten | Grundlage für Auftrag, Routing und Kommunikation |
| Lieferschein | Lieferadresse, Positionen, Mengen, Terminbezug | Wichtig für Sendungsinhalt, Mengenlogik und Zustellung |
| Packliste | Colli, Maße, Gewichte, Verpackungseinheiten | Relevant für Kapazität, Be- und Entladeplanung |
| T1-Zolldokument | Verfahrensbezug, Warenwerte, Referenzen, Beteiligte | Relevant für Grenz-, Transit- und Zollprozesse |
| E-Mail-Text | Abholfenster, Lieferfenster, Sonderhinweise, Ansprechpartner | Oft der Ort, an dem operative Zusatzinfos versteckt sind |
Wichtig ist dabei: Die relevanten Daten stehen in der Praxis oft nicht nur im PDF. Ein Teil steht im Mail-Body, ein Teil in einem Scan, ein Teil auf Seite zwei der Packliste. Genauso deshalb ist ein reiner „Datei öffnen und abtippen“-Prozess so ineffizient.
Der eigentliche Hebel heißt Management by Exception
Der größte Gewinn entsteht nicht dadurch, dass ein System jeden einzelnen Auftrag zu 100 Prozent autonom verarbeitet. Der größte Gewinn entsteht dadurch, dass der Regelfall verschwindet.
Wenn der KI-Agent 70, 80 oder 90 Prozent der sauberen Standardfälle vorbereitet und nur noch die schwierigen Fälle an Menschen eskaliert, verändert sich die Arbeit in der Disposition fundamental. Das Team bearbeitet dann nicht mehr die Masse, sondern die Ausnahmen.
Disponenten werden nicht ersetzt. Sie werden aus dem Abtippen herausgeholt und genau dort eingesetzt, wo Erfahrung, Kontext und schnelle Entscheidungen wirklich zählen.
Typische Ausnahmen sind:
- fehlende Lieferadresse,
- widersprüchliche Gewichtsangaben,
- unleserliche Scans,
- ungewohnte Dokumenttypen,
- unklare Gefahrgutangaben,
- abweichende Stammdaten,
- neue Kundenreferenzen,
- niedrige Sicherheit bei extrahierten Feldern.
Was technisch für die TMS-Automatisierung gebraucht wird
Die gute Nachricht: Für diesen Use Case muss kein komplettes TMS ersetzt werden. In vielen Fällen reicht eine zusätzliche Verarbeitungsschicht zwischen Eingangskanal und bestehendem System.
| Baustein | Aufgabe |
|---|---|
| E-Mail- oder Dokumenteneingang | Nimmt PDFs, Scans, E-Mails und Anhänge automatisiert entgegen. |
| Dokumentklassifizierung | Erkennt Dokumenttyp und Inhalt. |
| Datenextraktion | Liest relevante Felder strukturiert aus. |
| Validierungslogik | Prüft Pflichtfelder, Plausibilität und Geschäftsregeln. |
| Stammdatenabgleich | Ordnet bekannte Kunden, Orte, Artikel oder Relationen zu. |
| Schnittstelle zum TMS | Legt einen Auftrag an oder übergibt die Daten an einen Vorprüfungsstatus. |
| Exception Queue | Zeigt nur problematische Fälle dem Team zur Prüfung an. |
| Monitoring | Misst Durchlaufzeit, Fehlerarten, Ausnahmequote und Automatisierungsgrad. |
Entscheidend ist nicht, ob das System „KI“ draufschreibt. Entscheidend ist, ob die Daten am Ende sauber, nachvollziehbar und schnell im TMS landen.
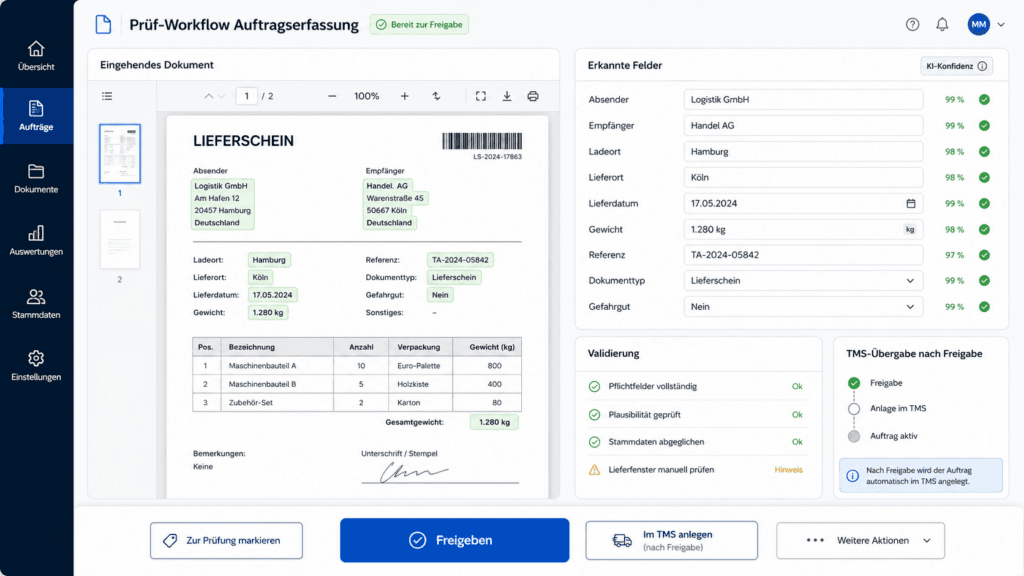
Warum die Schnittstelle wichtiger ist als das KI-Modell
Viele KI-Projekte sehen in der Demo beeindruckend aus. Ein PDF wird hochgeladen, Felder werden erkannt, alles wirkt sauber. Die entscheidende Frage kommt aber danach: Was passiert mit den Daten?
Für Speditionen reicht es nicht, wenn ein Tool erkannte Werte in einer hübschen Oberfläche anzeigt. Der Wert entsteht erst, wenn daraus ein nutzbarer Auftrag im TMS wird. Dafür braucht es eine saubere Übergabe.
- Direkte API-Anbindung an das TMS, wenn verfügbar.
- Middleware, wenn mehrere Systeme beteiligt sind.
- CSV- oder XML-Import, wenn das Bestandssystem keine moderne Schnittstelle bietet.
- Vorprüfungsstatus im TMS, wenn Daten zuerst freigegeben werden sollen.
- Rückmeldung an den Agenten, wenn ein Auftrag nicht sauber angelegt werden konnte.
Genau deshalb sollte die technische Konzeption nicht beim Dokument starten, sondern beim Zielsystem. Welche Felder braucht das TMS zwingend? Welche Werte müssen normiert werden? Welche Stammdaten müssen abgeglichen werden? Welche Fehler darf das System gar nicht erst importieren?
Validierung: Der Unterschied zwischen Demo und produktivem Prozess
Datenextraktion allein reicht nicht. Entscheidend ist die Validierung danach.
Ein KI-Agent sollte nicht einfach alle erkannten Daten ungeprüft ins TMS schreiben. Er muss fachliche Regeln prüfen und unklare Fälle sauber eskalieren. Genau hier trennt sich Spielerei von produktiver Automatisierung.
| Prüfung | Beispiel | Reaktion des Agenten |
|---|---|---|
| Pflichtfeldprüfung | Lieferadresse fehlt. | Auftrag nicht automatisch übergeben, sondern zur Prüfung markieren. |
| Plausibilitätsprüfung | Einzelgewichte ergeben nicht das angegebene Gesamtgewicht. | Abweichung anzeigen und Freigabe verlangen. |
| Stammdatenabgleich | Kunde oder Ladeort ist nicht bekannt. | Vorschlag machen oder neuen Datensatz zur Prüfung geben. |
| Formatprüfung | Referenznummer passt nicht zum erwarteten Muster. | Warnhinweis setzen. |
| Risikoprüfung | Gefahrgutangabe ist unvollständig oder widersprüchlich. | Automatische Übergabe blockieren und eskalieren. |
Das Ziel ist nicht blinde Automatisierung. Das Ziel ist kontrollierte Automatisierung.
Woran viele Projekte in der Praxis scheitern
- Zu breit gestartet: Zehn Dokumenttypen auf einmal automatisieren zu wollen, ist fast immer unnötig.
- Keine Feldpriorisierung: Nicht jedes Dokumentfeld ist für die Disposition gleich wichtig.
- Kein Ausnahmeprozess: Wenn unklare Fälle nirgends sauber landen, staut sich die Arbeit nur an anderer Stelle.
- Fehlender Stammdatenbezug: Ohne Abgleich mit Kunden, Orten oder Relationen bleibt zu viel manuelle Nacharbeit.
- Kein klares Zielbild: Wer nur „Dokumente digitalisieren“ will, bekommt oft schöne Technik, aber keinen messbaren operativen Effekt.
- Zu wenig echte Testdaten: Drei perfekte Beispiel-PDFs sagen nichts über den Alltag im Postfach aus.
- Keine Erfolgsmessung: Ohne Durchlaufzeit, Fehlerquote und Ausnahmequote bleibt der Nutzen gefühlt statt belegbar.
Der beste Start ist fast immer operationalisiert und eng geschnitten: ein Eingangskanal, zwei oder drei häufige Dokumenttypen, wenige wirklich kritische Felder und eine klare Definition, wann freigegeben und wann eskaliert wird.
So solltest Du das Projekt aufsetzen
- Dokumente sammeln: Welche Formate kommen wirklich im Alltag an?
- Datenfelder priorisieren: Welche Felder braucht das TMS zwingend für einen dispo-fähigen Auftrag?
- Ausnahmen definieren: Bei welchen Abweichungen soll das Team eingreifen?
- Schnittstelle klären: Direkte API, Middleware oder Importlogik im Bestandssystem?
- Pilot starten: Erst mit begrenztem Volumen und wenigen Dokumenttypen live gehen.
- Ergebnisse messen: Bearbeitungszeit, Ausnahmequote, Fehlerbilder und Durchlaufzeit vergleichen.
- Regeln nachschärfen: Wiederkehrende Ausnahmen analysieren und den Prozess gezielt verbessern.
- Skalieren: Erst danach weitere Dokumenttypen, Kunden oder Eingangskanäle anbinden.
Das Entscheidende dabei: Kein Technologiedemo-Projekt bauen, sondern einen Prozesshebel im Tagesgeschäft.
Für wen sich KI-Auftragserfassung besonders lohnt
Der Hebel ist besonders groß, wenn mehrere der folgenden Punkte zutreffen:
- hohes tägliches Auftragsvolumen,
- Aufträge kommen überwiegend per E-Mail und PDF,
- mehrere Dokumenttypen pro Sendung,
- wiederkehrende manuelle Erfassungsarbeit im Team,
- Personalmangel in Dispo oder Backoffice,
- späte Fehlererkennung erst bei Umschlag, Zustellung oder Abrechnung,
- bestehendes TMS ist vorhanden, aber der Auftragseingang bleibt analog,
- Kunden schicken unterschiedliche Formate statt sauberer EDI-Daten.
Gerade mittelständische Speditionen sitzen oft genau zwischen zwei Welten. Das TMS ist vorhanden. Die Dispo arbeitet digital. Aber der Auftragseingang hängt noch an PDFs, E-Mails und manueller Erfassung. Genau dort entsteht der Engpass.
Welche Kennzahlen Du vor und nach der Automatisierung messen solltest
Damit KI-Auftragserfassung nicht zur Bauchgefühl-Initiative wird, sollte der Prozess vor und nach dem Pilot gemessen werden.
| Kennzahl | Warum sie wichtig ist |
|---|---|
| Durchschnittliche Erfassungszeit pro Auftrag | Zeigt den direkten Zeithebel im Backoffice. |
| Aufträge pro Mitarbeiter und Tag | Macht Produktivitätsveränderungen sichtbar. |
| Fehlerquote bei Pflichtfeldern | Zeigt, ob die Datenqualität steigt oder sinkt. |
| Ausnahmequote | Zeigt, wie viele Fälle noch menschliche Prüfung brauchen. |
| Durchlaufzeit vom Posteingang bis TMS-Auftrag | Zeigt, wie schnell Aufträge dispo-fähig werden. |
| Rückfragenquote | Zeigt, ob Kunden- und interne Klärschleifen abnehmen. |
| Automatisierungsgrad je Dokumenttyp | Zeigt, welche Dokumente bereits gut funktionieren und wo nachgeschärft werden muss. |
Diese Kennzahlen helfen auch intern. Denn ein KI-Projekt lässt sich leichter begründen, wenn nicht nur von Innovation gesprochen wird, sondern von weniger Erfassungszeit, weniger Fehlern und schnellerer Auftragsanlage.
Datenschutz und Sicherheit nicht vergessen
Bei Transportaufträgen geht es nicht nur um Frachtdaten. Oft enthalten Dokumente auch personenbezogene Daten, Kundendaten, Ansprechpartner, Telefonnummern, Adressen oder sensible Geschäftsinformationen. Deshalb gehört Datenschutz von Anfang an in die Architektur.
- Wo werden PDFs verarbeitet?
- Wer hat Zugriff auf Dokumente und extrahierte Daten?
- Werden Prompts, Logs oder Zwischenergebnisse gespeichert?
- Wie lange werden Dokumente und Verarbeitungsergebnisse aufbewahrt?
- Gibt es einen AVV mit dem Anbieter?
- Werden Daten innerhalb der EU verarbeitet?
- Welche Subunternehmer sind beteiligt?
- Wie werden Fehler und manuelle Korrekturen protokolliert?
Datenschutz ist hier kein Zusatzthema. Er entscheidet mit darüber, ob die Lösung dauerhaft tragfähig ist.
Fazit: Das PDF-Chaos ist kein Naturgesetz
In vielen Speditionen wird heute noch so gearbeitet, als wäre das Öffnen, Lesen und Eintippen von Dokumenten ein notwendiger Teil der Disposition. Ist es nicht.
Ein moderner KI-Agent kann eingehende Dokumente klassifizieren, relevante Daten extrahieren, sie validieren und sauber an das TMS übergeben. Der Disponent greift dann nur noch dort ein, wo Kontext, Erfahrung oder Klärung gefragt sind.
Genau das ist der eigentliche Fortschritt: weg vom Abtippen, hin zu einem steuerbaren, skalierbaren Eingangsprozess.
Die Frage ist also nicht, ob Deine Disposition mit PDFs leben kann. Die Frage ist, warum sie es im Jahr 2026 noch immer muss.
FAQ: KI-Auftragserfassung in der Spedition
Ersetzt ein KI-Agent das TMS?
Nein. In den meisten Fällen ergänzt der Agent das bestehende TMS. Er automatisiert den Auftragseingang und übergibt strukturierte Daten an das System, das bereits im Einsatz ist.
Geht das nur mit sauberen Standardformularen?
Nein. Moderne KI-gestützte Dokumentenverarbeitung ist gerade dafür gedacht, mit variierenden Layouts, unterschiedlichen Dokumenttypen und gemischten Eingangskanälen umzugehen.
Muss der Prozess vollautomatisch sein, damit es sich lohnt?
Nein. Schon wenn Standardfälle automatisiert vorbereitet und nur noch Ausnahmen manuell geprüft werden, entsteht ein deutlicher operativer Hebel.
Womit sollte eine Spedition starten?
Mit einem klar abgegrenzten Pilot: einem Eingangskanal, wenigen Dokumenttypen und den Datenfeldern, die wirklich für die Auftragsanlage im TMS gebraucht werden.
Was ist der Unterschied zwischen OCR und KI-Auftragserfassung?
OCR liest Text aus Dokumenten. KI-Auftragserfassung geht weiter: Sie erkennt Dokumenttypen, extrahiert relevante Felder, prüft Plausibilität und bereitet strukturierte Daten für das TMS vor.
Welche Dokumente lassen sich automatisiert verarbeiten?
Typische Dokumente sind Frachtbriefe, Lieferscheine, Packlisten, T1-Zolldokumente, Rechnungen, E-Mail-Texte, Excel-Anhänge und weitere transportrelevante Unterlagen.
Ist eine TMS-Schnittstelle zwingend nötig?
Für echte Automatisierung ja. Ohne Übergabe ans TMS bleibt die Lösung eine reine Extraktionshilfe. Der operative Nutzen entsteht erst, wenn die Daten im Zielsystem landen oder dort zur Freigabe bereitstehen.
Nächster Schritt
Prüfen, ob ein konkreter Vorgang bei Euch geeignet ist.
Kommentare
Noch keine Kommentare. Sei der erste.
Weiterlesen
Mensch vs. Maschine? Wie KI-Agenten die Rolle der Disponenten aufwerten
Montagmorgen, 7:00 Uhr: 30 neue E-Mails, fehlende Frachtbriefe, Lkw-Fahrer warten auf Rückmeldung.
KI und DSGVO: Wie Unternehmen KI-Agenten datenschutzkonform einsetzen
DSGVO und Künstliche Intelligenz schließen sich nicht aus. Sie verlangen lediglich klare Architektur-Entscheidungen.
KI in der Steuerkanzlei: 3 Prozesse, die Du heute schon risikofrei automatisieren kannst
Steuerberatung ist ein konservatives Geschäft. Zu Recht: Wer täglich mit sensiblen Mandantendaten und harten Fristen hantiert, kann sich keine Experimente erlauben.